결정론적 하네스 8가지 기법
이 글에서 다룰 것
AI한테 코드를 맡겨두고도, 결과가 제대로 나올지 마음 한켠이 늘 두근거리지 않나요? 분명 명시적으로 지시를 줬는데도 AI가 그대로 따르는 비율이 생각보다 낮아요. 같은 말을 줘도 어떤 날은 이렇게, 어떤 날은 저렇게 나오고요.
사실 이건 어쩔 수 없는 면이 있어요. 우리가 자연어로 "대화"해서 시키는 거니까요. AI를 쓰는 것 자체가 비결정론적(같은 입력이어도 결과가 달라질 수 있는)인 일이거든요. 그래도 같은 상황이면 같은 결과가 나오면 좋겠다 — 이 이상에 최대한 가까이 가보자는 게 오늘의 목표예요.
그 방향이 결정론적(deterministic) 접근이고, 핵심 전략은 딱 하나로 좁혀져요 — AI가 알아서 결정하는 영역을 좁히는 것. 오늘은 그 영역을 좁히는 8가지 기법을 카탈로그처럼 훑어볼게요. 전부 다 할 필요는 없어요. 하나만 적용해도 그날부터 코딩이 한결 덜 두근거리거든요.
핵심 메시지
먼저 짚고 갈 게 있어요. AI는 왜 매번 다른 결과를 낼까요? 크게 세 군데에서 흔들려요.
첫째는 입력을 해석하는 단계. 같은 문장을 줘도 매번 조금씩 다르게 읽어요. 둘째는 도구를 고르는 단계. 어떤 도구를 쓸지, 어떤 파라미터로 부를지가 그때그때 달라지죠. 셋째는 다 됐다고 판단하는 단계. 어떤 날은 "문법 에러 없으니 됐네" 하고 끝내고, 어떤 날은 테스트까지 돌려보고요. 이 세 군데가 다 열려 있으니 결과가 매번 다를 수밖에 없는 거예요.
그래서 전략은 이 열린 자리를 하나씩 사람 쪽으로 가져와 좁히는 것이에요. 구현 범위든, 판단 규칙이든, 합격 기준이든 — AI가 알아서 정하던 걸 미리 정해두는 거죠. 아래 8가지가 전부 그 "좁히기"의 서로 다른 도구예요.
명시적으로 지시해도 AI가 그대로 따르는 비율은 생각보다 낮습니다. 그러니 말로 부탁하는 데서 멈추지 말고, 결정할 자리를 점점 코드 쪽으로 옮겨두자는 거예요.
1. Architecture-First - 큰 그림은 사람이 먼저
AI한테 기능을 통째로 던지면 구조도 자기가 알아서 잡아요. 문제는 AI가 종종 제일 손쉬운 자리에 코드를 욱여넣는다는 거예요. 규칙이 없으면 controller 안에 비즈니스 로직이 슬그머니 들어가 있고, 그런 게 쌓이면 나중에 손대기 무서운 코드가 되죠.
그래서 큰 그림은 사람이 먼저 그려둡니다. 디자인 가이드라인, 인터페이스, 함수·클래스 시그니처, 그리고 모듈 사이의 흐름 정도를 미리 정리해두면, AI는 그 안에서 구현만 하게 돼요. 결정 영역에서 "큰 그림"은 빼고 "구현 패턴"만 남기는 거죠.
가장 쉬운 형태는 레이어 규칙이에요. 디렉토리를 나누고, 각 디렉토리 안 파일이 무슨 역할까지 맡는지를 짧게는 규칙으로, 길게는 예제 코드까지 곁들여 정해둡니다. 프론트엔드라면 이런 식이고요,
src/
├── components/ # 순수 UI, 상태 없음
├── containers/ # 상태 + 비즈니스 로직
├── hooks/ # 커스텀 훅
├── services/ # API 호출만
└── store/ # 전역 상태 (zustand)
백엔드라면 이런 식이겠죠.
src/
├── routes/ # 라우팅만
├── controllers/ # 요청/응답 처리
├── services/ # 비즈니스 로직
├── repositories/ # DB 접근만
└── models/ # 데이터 구조
여기에 더해 선언적으로 못박아두면 더 좋아요 — "Components는 순수 함수만", "API 호출은 services에서만", "로컬 상태는 useState·서버 상태는 react-query·전역은 zustand·URL은 useSearchParams", "DB 접근은 repositories에서만, 비즈니스 로직은 services에서만, controller는 services만 호출"처럼요. 말로 풀면 길지만, 한 번 정해두면 매번 같은 자리에 같은 코드가 쌓입니다.
주의 — AI는 정말로 제일 쉬운 곳에 코드를 넣으려는 경향이 있어요. "알아서 잘"이 아니라, 어디에 무엇을 두는지를 먼저 손에 쥐여줘야 합니다.
2. Context Engineering - 프롬프트를 설계하기
"리팩토링 멋지게 해줘~" 하면 AI는 잘 해내요. 진짜 문제는 그 방향이 내가 원하던 방향이 맞느냐예요. 멋지게는 했는데, 우리 팀이 생각하는 리팩토링과는 다른 거죠.
그래서 프롬프트도 설계가 필요해요. 좋은 프롬프트엔 세 축이 있어요 — 범위 / 형식 / 기준. 문장 하나 툭 던지는 게 아니라, 코드를 먼저 분석해서 "여기 이 지점을 이렇게 바꾸자"까지 짚어주는 거죠. (이 짚어내는 작업조차 AI한테 먼저 검토시키고, 그 결과로 방향을 정해도 좋고요.)
막연한 "리팩토링" 대신 이렇게 구체적으로요.
- 추출(Extract): "UserCard에서 날짜 포맷팅 로직을
formatDate유틸 함수로 추출해줘. 동작 변경 없이." - 구조 변경: "중첩 if문을 early return 패턴으로 바꿔줘. 로직 변경 없이 구조만."
- 의존성 역전(DIP): "UserService가 MySQLUserRepository를 직접 import하는 부분을 IUserRepository 인터페이스에 의존하도록 바꿔줘. 테스트는 MockUserRepository로 교체."
- DRY: "loginHandler·signupHandler에 중복된 JWT 검증 로직을
validateToken미들웨어로 분리해줘."
출력의 형태가 중요하면 한 발 더 나가도 돼요 — 출력 스키마를 아예 강제하거나, 타입을 함께 줘서 그걸 기준으로 짜게 하거나, 예시를 1~2개 보여주는(few-shot) 식으로요.
주의 — 여기서 착각하기 쉬운 게 하나 있어요. "더 명확하게"가 "더 길게"는 아니라는 거예요. 컨텍스트가 비대해지면 오히려 AI가 지침을 제대로 못 가려내고, 토큰도 낭비돼요. 길게가 아니라 또렷하게, 가 핵심이에요.
3. Plan Mode - 구현 전에 계획을 같이 보기
AI가 머릿속에 세운 계획, 여러분은 보이세요? 들여다보지 않으면 몰라요. 그냥 "좋아요, 구현 시작할게요" 하고 달려가 버리죠. 근데 분명 그 안엔 계획이 있었거든요.
Plan Mode는 그 계획을 구현 전에 꺼내 같이 보는 명시적 승인 게이트예요. AI가 접근을 글로 쭉 내놓으면, 사람이 읽어보고 "X 말고 Y로 가자" 하고 합의한 다음에야 구현으로 넘어가는 거죠. 틀린 방향을 0줄에서 잡으니, 두 번 개발하지 않고 한 번에 끝낼 확률이 올라가요.
주의 — 계획이 너무 크게 한 덩어리로 나오면 읽기도 벅차요. 그럴 땐 plan 자체를 쪼개고, 특히 중요하거나 위험한 작업은 별도 확인 절차로 떼어내는 게 좋아요.
4. CLAUDE.md - 제안이지, 강제가 아니다
"규칙을 전부 CLAUDE.md에 적어두면 되지 않나?" 한 번쯤 이렇게 생각하게 되죠. 그런데 거기 분명히 적어놨는데도 안 지켜진 경험, 없으세요? 가끔 이런 일이 있거든요.
이유가 두어 가지 있어요. 세션이 길어지면 CLAUDE.md의 규칙이 점점 흐려져요. 그리고 거기 적힌 규칙과 대화 중에 생긴 규칙이 충돌하면, 보통 대화 쪽이 우선돼요. "원래 기본 규칙은 이거지만, 지금 상황에선 이게 더 중요하니까" 하고 AI가 스스로 판단해버리는 거죠.
그래서 CLAUDE.md(나 AGENT.md)는 "기본 상태를 안정화하는 도구"이지, "강제 메커니즘"이 아니에요. AI가 지킬 확률은 높이지만 보장은 못 해요. 이 한계를 인정하고, 꼭 지켜져야 하는 건 뒤에 나오는 기법들(특히 Hooks)로 받쳐줘야 합니다.
5. Slash Command & Skill - 같은 입력을 재생하기
프롬프트를 매번 새로 입력하면, 입력 자체가 매번 달라지는 셈이에요. 비결정론의 출발점이 바로 거기죠.
그래서 자주 하는 일은 고정된 프롬프트로 묶어 재생해요. 대표적인 게 슬래시 커맨드, 그리고 스킬이고요. 한 번 잘 만들어두면 같은 입력이 보장되니 출력도 한결 안정돼요. 예를 들어 "함수 추출"을 이렇게 한 커맨드로 박아둘 수 있어요.
---
description: 함수 일부를 별도 함수로 추출 (동작 변경 없음)
---
다음을 정확히 이 순서로 수행:
1. $ARGUMENTS에서 지정한 대상 코드 식별
2. 추출할 블록을 camelCase 함수명으로 분리
3. 호출부 자동 수정
4. 기존 테스트 실행으로 동작 변경 없음 검증
5. 변경된 파일 목록만 보고. 다른 변경 금지.
한 가지 기억할 건, 스킬도 코드처럼 유지보수 대상이라는 거예요. 버전 관리하고, PR 리뷰도 받고요. 내용은 명확하고 간결하게. 그리고 스킬이 다른 스킬을 부르기 시작하면 의존성이 생겨서 "이거 고쳐도 되나?" 싶어지는데, 이건 모듈 관리하듯 가능한 한 독립적으로 두는 게 편해요.
6. Hooks - 100% 강제가 필요할 때
"main에 직접 푸시 금지", "구현 코드엔 정적 검사 필수" — 이런 건 어디다 둬야 할까요? CLAUDE.md에 적으면? 앞에서 봤듯이 반드시 지켜진다는 보장이 없죠.
정말 100% 지켜야 하는 건 코드로 강제해요. 그게 Hooks예요. 핵심 원칙은 "정확한 타이밍에, 프로그래밍적으로." CLAUDE.md로는 제안하고 Hooks로는 강제하는 거죠. 말 그대로 검사는 코드로 — 그래야 강한 결정론이 됩니다.
타이밍은 둘이에요. 실행 전(PreToolUse)엔 위험한 명령을 차단하고, 실행 후(PostToolUse)엔 결과가 합격선을 넘었는지 검사해요.
| 시점 | 역할 | 예시 |
|---|---|---|
| 실행 전 (PreToolUse) | 위험한 명령 차단 | rm, push, 외부 curl 호출 등 |
| 실행 후 (PostToolUse) | 결과 합격선 검사 | 테스트·타입·lint 통과 |
훅은 거의 100% 실행되니까, 한 번 걸어두면 빠져나갈 구멍이 없어요. 예를 들어 코드가 수정될 때마다 타입 체크와 lint를 강제하는 훅은 이렇게 생겼어요.
{
"hooks": {
"PostToolUse": [{
"matcher": "Edit|Write",
"hooks": [{
"type": "command",
"command": "tsc --noEmit && eslint $(jq -r .tool_input.file_path)"
}]
}]
}
}
재밌는 부수 효과도 있어요. AI가 "한 번 수정했더니 매번 검사가 도네? 그럼 이걸 잘 지켜야겠네" 하고 세션 안에서 스스로 학습하기도 하거든요. 빠르게 결정론을 들이는 좋은 출발점이에요.
7. TDD - 테스트를 먼저 박아두기
구현이 끝나고 나면 이런 의심이 들죠 — "이거 다 된 거 맞나? 믿을 만한 품질인가? 시키지도 않은 게 끼어들진 않았나?" 실제로 이런 일은 비일비재해요.
TDD는 그 불안을 앞쪽에서 잠재워요. 결정된 spec만, 딱 그만큼만 구현하게 만드는 거죠. spec을 정하고 → 테스트 시나리오로 풀고 → 그 시나리오대로만 테스트를 짜고 → 거기에 맞춰서만 구현하고 → 마지막에 자동 검증. AI의 개발 범위를 미리 좁혀두고, 끝에서 기계적으로 확인하는 구조예요.
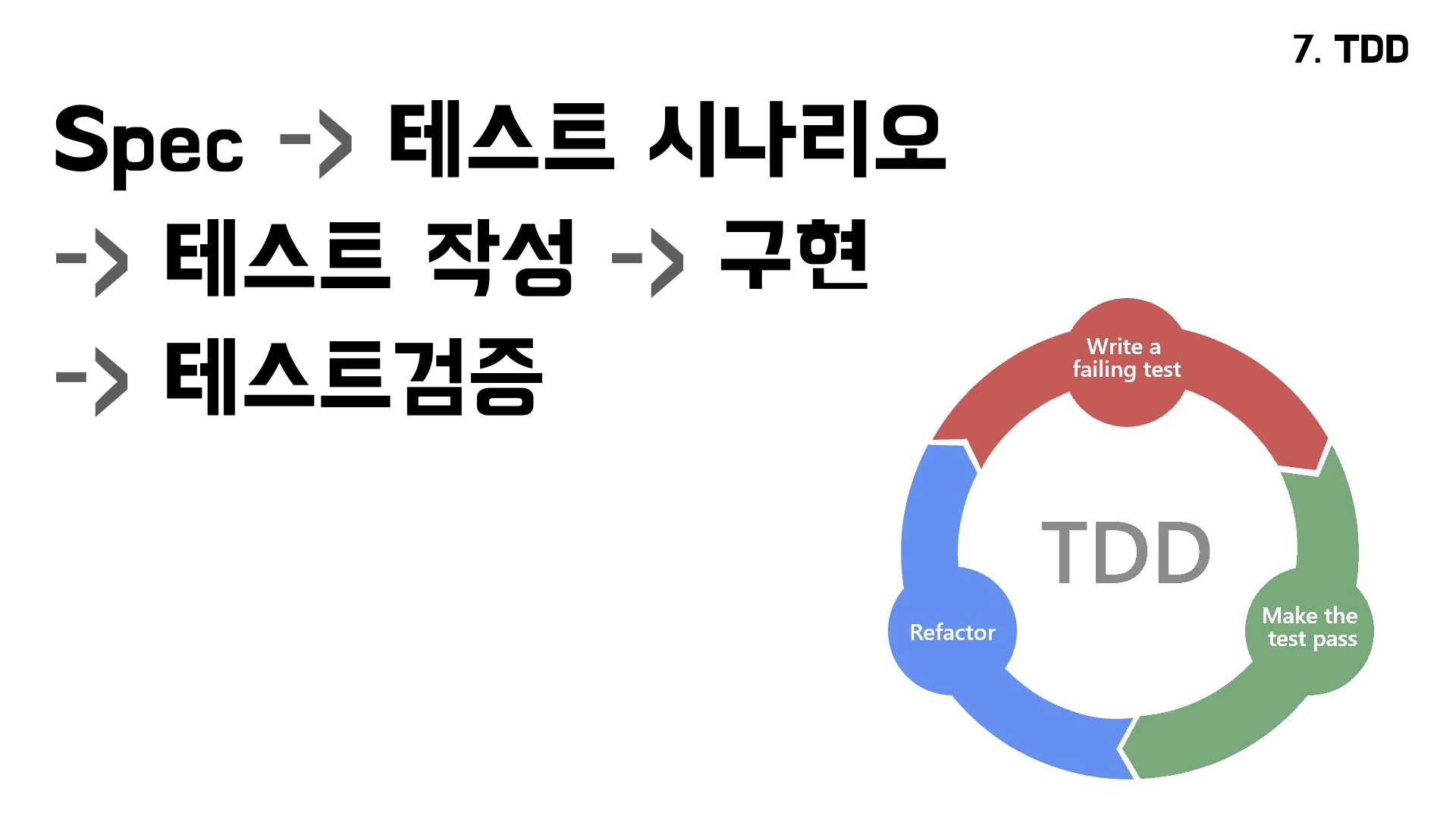 TDD 사이클 (Spec→Scenario→Test→Code→Verify)
TDD 사이클 (Spec→Scenario→Test→Code→Verify)
8. Observability - AI가 한 일을 들여다보기
AI가 뭔가 만들긴 했는데 조용히 망하는 경우가 있어요. 잘못된 방법으로 고쳐놓고도 결과만 그럴듯한 가짜 성공, 그리고 같은 걸 몇 번씩 재시도하는 경우도요. 좀 의심스럽지 않나요?
그래서 AI가 한 일을 로그로 남겨 들여다봐요. 어떤 도구를 어떻게 불렀는지, (가능하면) 왜 그런 결정을 했는지, 무슨 훅이 발동돼 뭘 막았는지, 재시도는 몇 번이나 했는지 — 이런 걸 타임스탬프와 함께 남기는 거죠.
| 항목 | 무엇을 보나 |
|---|---|
| Tool call log | AI가 어떤 도구를 어떻게 불렀나 |
| Reasoning trace | (가능하다면) 왜 그런 결정을 했나 |
| Hook 발동 이력 | 무엇이 차단됐나 |
| Retry 횟수 | 수상한 반복은 없나 |
모든 도구 호출을 로그로 남기는 훅은 이렇게 간단히 만들 수 있어요.
{
"hooks": {
"PostToolUse": [{
"matcher": ".*",
"hooks": [{
"type": "command",
"command": ".claude/hooks/log-tool.sh"
}]
}]
}
}
남긴 로그는 그냥 쌓아두는 게 아니라, AI한테 "이거 분석해줘" 하고 되물어도 되고, 시각화해서 전체를 훑어봐도 돼요. "어, 리트라이 횟수가 자꾸 늘어나는데 뭐가 문제지?" 같은 진단이 그제서야 눈에 들어오거든요.
어디부터 적용하나 - 소프트에서 하드로
8가지를 한꺼번에 다 깔 필요는 없어요. 강도가 다르거든요.
소프트 결정론(안정화) 쪽은 부드럽게 방향을 잡아주는 도구들이에요 — Architecture-First, Context Engineering, Plan Mode, CLAUDE.md. 하드 결정론(강제) 쪽은 빠져나갈 구멍을 막는 도구들이고요 — Slash Command·Skill, Hooks, TDD, Observability.
처음엔 소프트부터 깔고, 신뢰가 필요한 자리에 하드를 하나씩 얹는 순서가 안전해요. 그리고 이 8가지가 한 개발 사이클로 어떻게 맞물리는지는 한 장의 그림으로도 정리돼 있어요.
 AI 하네스 워크플로우 12스텝 + META 2
AI 하네스 워크플로우 12스텝 + META 2
마무리 - 하나만 적용해도 달라져요
오늘 8가지를 쭉 봤지만, 한 줄로 줄이면 전부 같은 얘기예요 — AI가 알아서 정하던 자리를, 시작 전에 내가 먼저 정해두기. 그 자리를 어디까지 코드로 못박느냐가 소프트와 하드를 가를 뿐이고요.
| 기법 | 좁히는 자리 | 강도 |
|---|---|---|
| Architecture-First | 구조·레이어 | 소프트 |
| Context Engineering | 프롬프트의 범위·형식·기준 | 소프트 |
| Plan Mode | 구현 전 접근 합의 | 소프트 |
| CLAUDE.md | 기본 상태 안정화 | 소프트 |
| Slash Command & Skill | 입력 고정 | 하드 |
| Hooks | 합격선 강제 | 하드 |
| TDD | 구현 범위 + 검증 | 하드 |
| Observability | 결과 가시성 | 하드 |
전부 갖추려고 부담 가질 필요 없어요. 하나라도 적용하면, 그날부터 안 두근거리거든요! 마음 편한 자리 하나부터 골라서 시작해보세요.
참고 영상
